
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 백준
- 알고리즘
- coding test
- 내용추가
- 모두를 위한 딥러닝
- Python
- 프로그래머스
- reinforcement learning
- object detection
- 논문
- computer vision
- Today
- Total
NISSO
[Object Detection] Sliding Windows Detection 본문
- Sliding Windows Detection 이란
- Sliding Windows Detection 방법
- Sliding Windows Detection 단점
- Sliding Windows Detection 구조 (구현)
Sliding Windows Detection
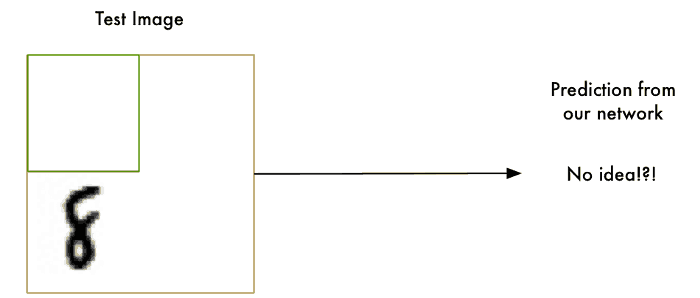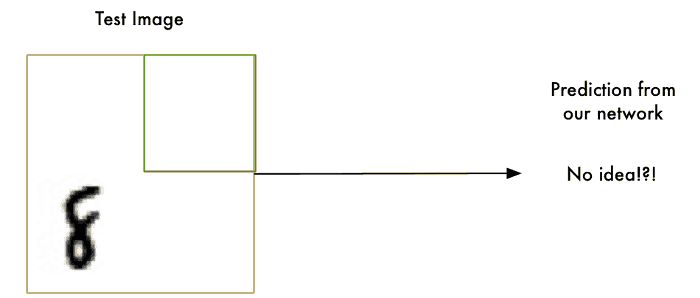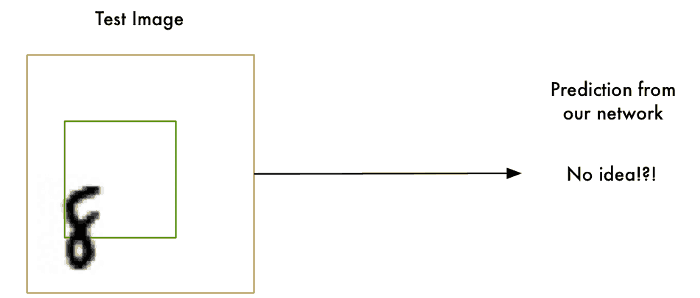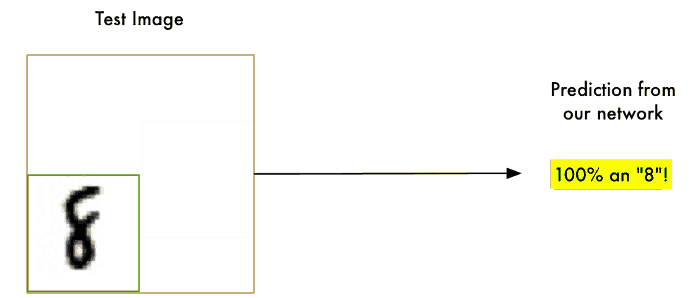
객체 위치를 식별하는 object localization의 하나로,
sliding window는 이미지에서 8이라는 객체 위치를 찾고 싶을 때, 그 객체를 찾을 때까지 모든 섹션을 확인해 탐지하는 방법이다.
Sliding Windows Detection 방법

위와 같이 이미지에서 자동차 객체를 탐지하려고 한다.

1. 차가 있는 이미지에서 차가 아닌 부분을 자르고 차만 남긴다.
2. 이미지 x에 따라 레이블 y는 차 1, 차가 아닌 경우 0으로 설정해 training set을 만든다.
3. labeling된 training set으로 CNN을 학습시킨다.

그럼 이와 같이 이미지 x를 입력했을 때 Convolution 신경망을 거쳐 레이블 y가 나온다.
자동차면 1, 아니면 0이 나올 것이다.
이제 이것을 위의 숫자 8 객체 검출과 같이 detection에 사용한다.



4. 특정 윈도우 크기를 선택해 윈도우를 조금씩 이동시키며 이미지의 일부분들을 모두 Convolution 신경망으로 학습시킨다.
그럼 각 윈도우 위치에 대해 0이나 1 값이 나올 것이다.

5. 마지막 부분까지 모두 학습시킨 후, 윈도우 크기를 조금 키워 똑같이 학습시킨다.
6. 윈도우 크기를 더 키워 똑같이 학습시킨다.
각 학습시킨 결과는 0과 1 값으로 나올 것이고, 어느 위치에 찾고자 하는 객체가 있는지 탐지할 수 있다.
Sliding Windows Detection의 단점
계산 비용 多 : 윈도우 크기에 따라 이미지를 모두 잘라내야 하고, 각각을 Convolution 신경망에 학습시켜야 한다.
계산 비용도 많이 들고 학습속도 또한 느리다.
슬라이드 간격(stride)을 키우면 신경망을 통과하는 윈도우 수는 줄겠지만, 성능이 저하될 수 있다.
반대로 윈도우 크기를 줄이거나 간격을 줄이면 계산 비용이 커진다.
이처럼 모든 윈도우 위치와 크기에 따라 매번 Convolution 신경망을 학습시키는 건 비효율적이다.
따라서 윈도우 크기에 따라서 한 번씩만 학습시키는 방법이 있다. 윈도우를 이동시키며 학습시키지 않아도 되는 것이다.
Sliding Windows Detection 구조
앞서 detection 방법에서, 이미지를 x로 입력해 Convolution layer를 거치면 1이나 0으로 결과값이 반환된다고 했다.
크기 14*14*3인 이미지를 입력하고 윈도우 크기와 간격을 크게 설정해 이미지를 4개의 윈도우 크기로 나눠 학습시킨다 해보자.
그럼 각 4개의 섹션 (이미지에서 4개의 윈도우 위치)에 따라 1과 0값이 4개가 나온다.
아래 예시에서 첫번째가 이를 나타내는 구조다.
이렇게 학습하면 윈도우 크기와 간격이 좁아 학습 회수가 많아지고 계산 비용이 많이 든다.
이를 해결하기 위해 윈도우 크기에 따라 한 번만 convolution layer를 학습시키려고 한다.

먼저 Fully connected layer를 Convolution layer로 바꾸는 방법을 알아야 한다.
위의 예시가 fully connected, 아래가 convolution layer로 변경한 그림이다.
Convolution + Fully Connected
14*14*3 크기의 이미지에서 5*5 필터 16개를 사용해 10*10*16으로 만든다.
2*2 maxpooling을 지나 5*5*16으로 줄어들고, flatten시키면 400개 유닛에 대한 fully connected layer가 된다.
하나의 fully connected layer와 softmax를 거쳐 윈도우 위치에 따라 결과값 4개가 출력된다.
Convolution
maxpooling 까지는 위와 같다.
5*5*16에 5*5 필터 400개를 사용해 1*1*400 크기의 colvolution layer로 연결시킨다. 수학적으로는 fully connected 와 같다.
(이 때 5*5 필터는 16개 채널을 모두 통과할 수 있도록 만들어져있으므로 1*1이 되고 400개 필터를 통과해 1*1*400이 됨)
(fully connected layer에선 400개 노드의 집합이었다면, convolution layer에선 1*1*400의 볼륨이 되는 것)
여기에 다시 1*1*400 필터 400개를 만들어 똑같이 1*1*400이 되고, 이것 또한 fully connected와 동일하다.
마지막으로 또다른 1*1 필터 4개와 softmax를 거치면 1*1*4의 결과가 나온다.
fully connected가 출력한 4개의 숫자값을 의미한다.
다음은 드디어 윈도우로 colvolution을 구현한 방법이다. (편의상 입체 무시)


16*16*3 이미지를 14*14 크기의 윈도우에 대해 간격을 2로 하여 4개의 부분으로 나누어 학습시키려고 한다.
위에서 파란색은 윈도우, 노란색이 입력 이미지다. 마지막은 첫 윈도우 위치의 결과값이 파란색이다.
convolution + fully connected 구조는 윈도우를 이동시키며 각 4번을 학습시켜야 한다.
아래는 각 윈도우 위치를 초록, 빨강, 파랑, 보라색으로 표시했다.
그림1에서 아래 convolution layer 구조가 그림2의 윈도우 하나의 구조라고 생각하면 된다.
학습을 4번 수행하지 않고 한 번에 1*1*4 결과가 총 4번, 2*2*4의 결과로 나오는 것이다.
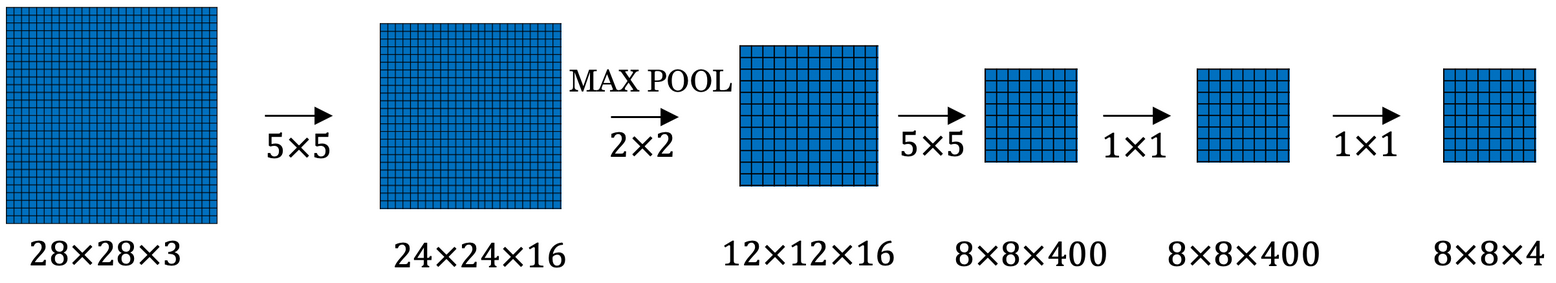

Sliding Windows Detection의 한 예시다.
28*28*3 크기의 이미지에서 14*14 윈도우를 사용했다.
윈도우를 이동시켜가며 (fully connected) 혹은 한 번에 (convolution) 학습시켜서 자동차의 위치를 찾았다.
참고자료
'Computer Vision' 카테고리의 다른 글
| [OpenCV] Template Matching (0) | 2021.11.16 |
|---|---|
| [개념정리] IOU (Intersection Over Union)와 mAP (mean Average Precision) (1) | 2021.10.12 |
| [용어] ML/DL에서 Ground-truth와 label의 차이 (0) | 2021.09.07 |
| [CBIR] Content-based Image Retrieval (2) | 2021.09.07 |



