
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python
- 백준
- 모두를 위한 딥러닝
- 알고리즘
- reinforcement learning
- computer vision
- 프로그래머스
- object detection
- 내용추가
- 논문
- coding test
- Today
- Total
NISSO
[논문 리뷰] [VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition 본문
[논문 리뷰] [VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition
oniss 2021. 10. 18. 14:25Very Deep Convolutional Networks for Large-Scale Image Recognition
* 대규모 이미지 인식을 위한 아주 깊은 컨볼루션 신경망
* Computer Vision 분야에 대한 큰 가능성을 보여줌
* VGG : Visual Geometry Group, 옥스포드대 연구팀 이름
https://arxiv.org/pdf/1409.1556.pdf
VGGNet은 CNN의 깊이에 따른 정확도를 연구할 목적으로 만든 이미지 인식 모델이다.
Abstract
- 대규모 이미지 인식에서 convolutional network의 깊이가 정확도에 미치는 영향을 조사
- 3*3 convolution filter 구조를 사용해 깊은 신경망을 평가
- 16-19 weight layer의 깊이로 선행 기술 개선 가능
- ILSVRC-2014의 localisation 우승, classification 준우승
* classification 우승은 GoogLeNet. 하지만 비교적 사용하기 쉽고 성능이 좋아 GoogLeNet보다 VGGNet을 더 많이 사용한다.
* googLeNet은 Inception 모델이다.
Introduction
- Convolutional Network (ConvNet)은 ImageNet이나 GPU 등으로 대규모 이미지 / 영상 인식에서 좋은 성능을 보임
- ILSVRC의 localisation, classification 과제에 대해 정확도를 높이는 구조를 고안
- 비교적 간단한 구조의 일부를 사용해도 다른 데이터셋에 적용했을 때 준수한 성능을 보이는 구조 고안 (ex. fine-tuning 없이 선형 SVM으로 feature 분류)
ConvNet Configurations
동일한 환경에서 ConvNet 깊이에 따른 정확도 향상을 측정하기 위해 모든 ConvNet layer 구조는 동일하게 설계
Architecture

- 입력은 224*224 크기의 RGB 이미지로 고정
- (각 픽셀 값) - (training set에서 계산된 RGB 평균값) 으로 전처리 : 수학적으로 정규화 개념과 비슷
- 3*3 filter 사용 : 상하좌우, 중앙의 feature를 포착하기 위한 가장 작은 크기, receptive field
- 1*1 filter 사용 : 입력 이미지의 channel에 대해 선형 변환 -> 비선형성 증가
- stride : 1px로 고정
- spatial padding : colvolution 연산 후, 공간 해상도 보존 / 3*3 conv layer에 대해 1px / 일부 layer에 MaxPooling 적용, 총 5 layers / 2*2px, stride=2
- 다양한 깊이의 Conv layer + 3 FC layer + softmax, Conv 깊이에 따른 FC layer 구조 동일
- 1,2 FC layer : 4096 channel
- 3 FC layer : 1000 channel (ILSVRC 데이터셋 class가 1000개)
- 모든 hidden layer는 ReLU 활성함수 적용, 마지막 layer만 softmax
- LRN (Local Response Normalization)은 적용 X : 메모리, 계산 시간 증가
* LRN : AlexNet에서 처음 도입하여, 활성화 함수 적용 전 Normalization을 적용해 일반화 능력을 향상시킴. 이미지의 인접화소들을 억제시키고 특징을 부각시키기 위해 사용. 밝은 빛을 보면 눈이 어두워지거나, 특정 사물에 집중하면 그 부분만 집중하여 보이게 되는 신경생물학적 현상
Configurations
- 위의 architecture를 따르고, 네트워크의 깊이를 달리한 구성이 각 A, A-LRN, B, C, D, E
- A : Conv 8 + FC 3의 11 weight layers / E : Conv 16 + FC 3의 19 weight layers
- Conv layer의 폭(채널 수)는 64에서 시작해 각 MaxPooling layer를 지나며 2배씩 증가해 마지막 layer에서 512
- 깊이에 따른 매개변수 개수는 비슷
* 굵은 글씨 : 추가된 layer
* parameter : (receptive field(3*3 filter) 크기) - (채널 수)
Discussion
- ILSVRC-2012, 2013 우승 모델들과 달리, 전체 네트워크에서 매우 작은 3*3 receptive field를 사용
- 7*7 filter 1개 대신 3*3 filter 3개를 사용함으로써, 3개의 비선형 layer를 통해 의사결정 기능이 더 명확해지고, 매개변수 개수를 감소시킬 수 있음
이게 무슨 말인지 알아보자.
먼저, "7*7 1개 대신 3*3 3개" 의미를 보자.

10*10 크기 이미지가 있다. 여기에 7*7와 3*3 필터를 각각 사용해 convolution 연산을 한다.
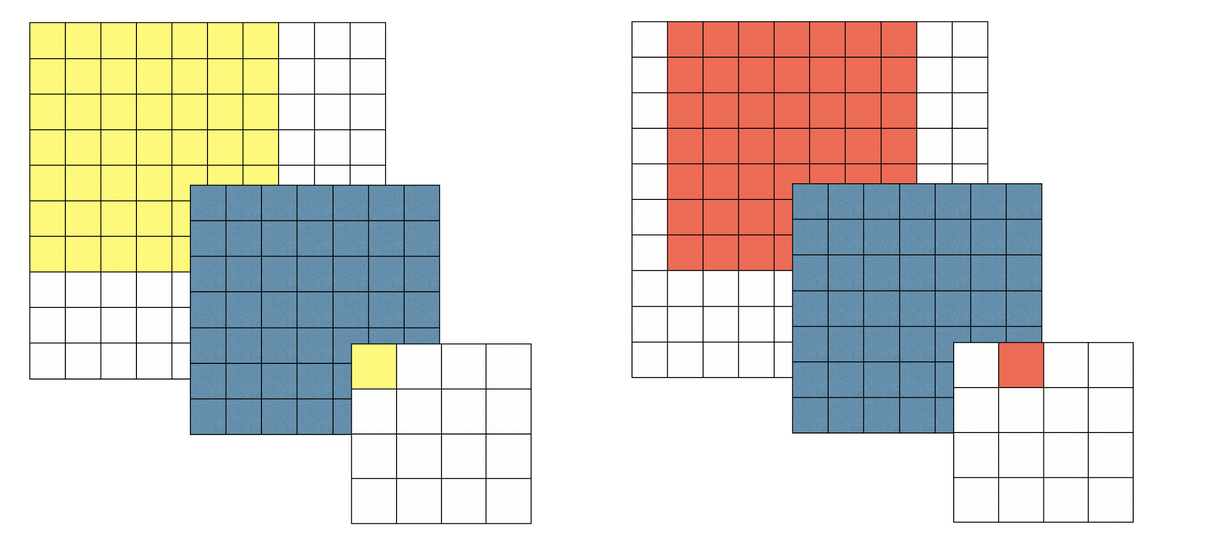
파란색이 7*7 필터다.
위와 같이 7*7 필터를 사용해 한 픽셀(블럭)씩 연산을 계속 해나가면 4*4 크기의 결과를 얻는다.
그럼 아래 3*3 필터 연산을 보자.
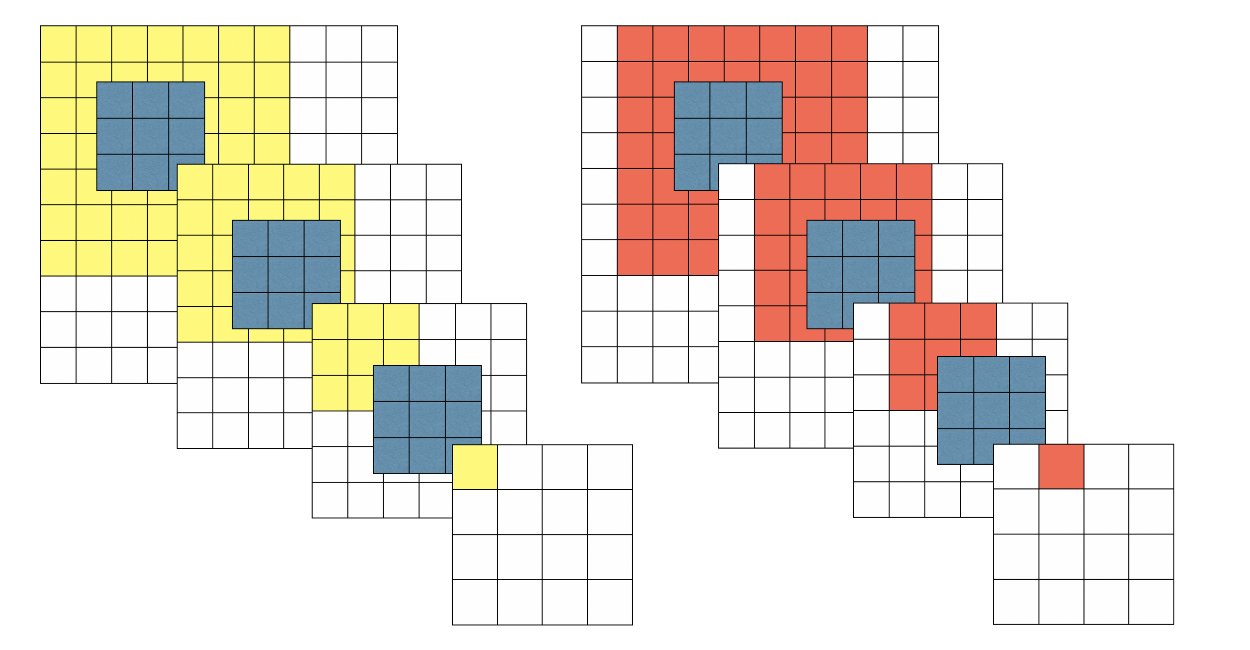
파란색이 3*3 필터다.
3*3 필터를 사용해 4*4 결과를 내기 위해 위와 같이 3번의 연산을 거쳐야 한다.
각 3번의 연산 결과는 다음과 같다.
- 10x10 이미지에 3x3 적용 -> 8x8
- 8x8 이미지에 3x3 적용 -> 6x6
- 6x6 이미지에 3x3 적용 -> 4x4
한 layer당 3*3 필터 연산이 한 번씩 이루어지므로 3번의 연산은 3개의 층에서 각각 일어난 것이다.
이는 7*7 필터를 사용해 연산한 layer 1개를 대체할 수 있다.
그럼 굳이 왜 더 작은 필터를 사용하면서 layer 개수를 늘리는 것일까?
위에서 언급한 바로는, 의사결정 기능이 더 명확해지고, 매개변수 개수를 감소시킬 수 있다.
전자는 비선형성 덕분이다.
예를 들어, 오늘 점심 메뉴를 정해야 하는 의사결정 시간이 왔다고 해보자.
1. 어제 저녁에 치킨을 먹었고, 오늘 저녁은 파스타를 먹기로 했고, 날씨가 더우니 뜨거운 건 싫고,, 등 7가지를 고려해 메뉴 선정
2. 어제 저녁메뉴가 치킨 -> 닭요리 제외
오늘 저녁 파스타 먹을 예정 -> 양식 제외
날씨가 더워 뜨거운 건 싫음 -> 탕 제외
1과 2는 결과는 비슷할 수 있지만 효과적이고 명확하게 메뉴를 결정할 수 있다.
7*7 필터 layer 1개 대신 3*3 필터 layer 3개를 사용한다고 했다.
각 layer는 ReLU 활성화함수를 갖고, ReLU를 통해 layer 내 수학적 연산이 끝난 값들이 0 또는 양수라는 단순한 값으로 변환된다.
연산 결과값들이 그대로 다음 layer에 전달되지 않고 ReLU를 통해 변형되어 전달되는 그 과정이 비선형성이다.
따라서 의사결정 기능이 명확해진다.
* 1*1 Conv layer로도 비선형성을 증가시킬 수 있으며, configuration 중 16 layer인 C 모델에서 사용했다.
매개변수 개수는 쉽게 계산할 수 있다.
1x(7x7) = 49
3x(3x3) = 27
이는 필터 크기가 클수록 차이가 많이 난다. 예를 들어 11*11 필터 대신 3*3 필터를 5개 사용한다고 할 때, 121과 45의 차이다.
따라서 작은 필터 여러 개를 사용하면 매개변수 개수가 줄고, 연산량이 줄어든다는 장점이 있다.
네트워크 깊이가 깊어진다고 매개변수 개수가 확연히 증가하지 않는 이유도 이것이다.
Classification Framework
Training
- multinomial logistic regression
- mini-batch gradient descent
- momentum = 0.9
- weight decay (L2 penalty) = 0.0005
- dropout (FC layer 1,2)
- learning rate = 0.01로 초기화, 점점 감소
- epochs = 74
- batch size = 256
- train 이미지 크기는 224*224 로 고정하는데, 방법은 아래와 같다.
각 이미지에 대해 크기를 최소값 256*256 ~ 최대값 512*512 사이 임의의 값으로 변환한다. (Multi-scale)

변환 후 각 이미지에서 object의 일부를 포함해 224*224 크기로 crop한다.


그럼 위와 같은 224*224 크기의 crop 이미지가 원본 이미지 한 장당 여러 개가 만들어지고, 여기에 수평반사 (random horizontal flipping) 를 적용해 2배 더 늘어난다.
이렇게 함으로써 데이터 양을 증강하고(Data Augmentation), 객체의 다양한 부분을 학습시켜 overfitting을 방지할 수 있다.
해당 논문에서는 속도상의 이유로 최소값과 최대값의 중간값인 384 (=(256+512)/2) 로 고정시켜 학습을 진행했다.
Testing
- 3개의 FC layer를 Fully Convolutional layer로 변환해 Fully Convolutional network로 테스트 진행
- multi-crop evaluation
Implementation Details
- Multi-GPU training : GPU 4개로 병렬처리해 속도 향상
Conclusion
네트워크 깊이가 깊어질수록 분류 정확도가 높다.
참고자료
VGG16 논문 리뷰 — Very Deep Convolutional Networks for Large-Scale Image Recognition
VGG-16 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥러닝 관련 대표적 연구 중 하나로 자리매김하였다.
medium.com
VGGNet — Organize everything I know documentation
When applying a ConvNet to a crop, the convolved feature maps are padded with zeros, while in the case of dense evaluation the padding for the same crop naturally comes from the neighbouring parts of an image (due to both the convolutions and spatial pooli
oi.readthedocs.io
'Paper Review' 카테고리의 다른 글
| [논문 리뷰] [RetinaNet] Focal Loss for Dense Object Detection (1) | 2022.06.20 |
|---|---|
| [논문 리뷰] [YOLOv1] You Only Look Once:Unified, Real-Time Object Detection (0) | 2022.04.07 |
| [논문 리뷰] [Faster R-CNN] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2021.10.28 |
| object detection 논문 흐름도 (0) | 2021.10.13 |



