
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- object detection
- 모두를 위한 딥러닝
- 논문
- 내용추가
- computer vision
- 백준
- Python
- reinforcement learning
- 알고리즘
- 프로그래머스
- coding test
- Today
- Total
NISSO
[논문 리뷰] [YOLOv1] You Only Look Once:Unified, Real-Time Object Detection 본문
[논문 리뷰] [YOLOv1] You Only Look Once:Unified, Real-Time Object Detection
oniss 2022. 4. 7. 17:15YOLO:: You Only Look Once:Unified, Real-Time Object Detection (2016)
https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
YOLO는 기존 모델들과 달리, single network 구조를 형성해 실시간 처리가 가능하도록 한 object detection 모델이다.
Abstract
- YOLO : object detection에 대한 새로운 접근 방식
- 단일 신경망은 evaluation 한 번으로 이미지의 bounding box와 클래스 확률을 즉시 예측
- 전체 detection 파이프라인이 단일 네트워크이므로 end-to-end detection 가능
- 초당 45프레임으로 실시간 이미지 처리
- localization 오류가 더 많지만 배경에 대해 false positive를 예측할 가능성은 낮다
(이미지에서 배경이 아닌 곳을 배경이라고 잘못 예측할 확률이 낮다)
Introduction
- 복잡한 파이프라인으로 구성된 기존 모델들과 달리, 이미지에서 bounding box 좌표와 클래스 확률을 즉시 예측함으로써 object detection을 단일 회귀 문제로 재구성
- 당신은 이미지를 한 번만 보고 (you only look once = YOLO!) 객체의 위치와 종류를 파악 가능
YOLO Detection System

- 448 × 448 로 input 이미지 resize
- 이미지에 대해 단일 convolutional network 실행 -> bounding box 좌표와 클래스 확률 동시 예측
- NMS : 모델의 신뢰도에 따라 detection 결과를 threshold(임계값)으로 지정
기존 방법과 비교한 YOLO의 장점
- YOLO is extremely fast.
- detection을 회귀 문제로 간주해 복잡한 파이프라인이 불필요
- YOLO : 45fps / fast YOLO : 150fps 이상의 실시간 처리 가능
- 다른 실시간 시스템에 비해 mAP가 2배 이상
- YOLO reasons globally about the image when making predictions.
- sliding window나 region proposal 기반 방법과 달리, 이미지 전체를 봄
- 이미지에 대해 contextual 정보를 얻을 수 있어, Fast R-CNN에 비해 배경 인식의 오류 수 절반 이상 감소
- YOLO learns generalizable representations of objects.
- object의 특정적 표현이 아닌 일반화된 표현을 학습하기 때문에 일반화 능력 우수
- 새로운 도메인이나 unexpected input에 대해 예측 성능이 비교적 좋음
- DPM이나 R-CNN보다 뛰어난 일반화 성능
YOLO의 단점
- 비교적 낮은 정확도
- 속도는 빠르지만, 일부 object, 특히 크기가 작은 object에 대한 detection이 어려움
Unified Detection
- YOLO는 구조가 하나로 통합되어 Single Neural Network 구조 형성
- 단 하나의 네트워크로 전체 이미지의 feature를 사용해 모든 클래스와 그에 대한 bounding box를 동시에 예측
- 즉, 전체 이미지와 이미지 내 모든 object에 대해 추론
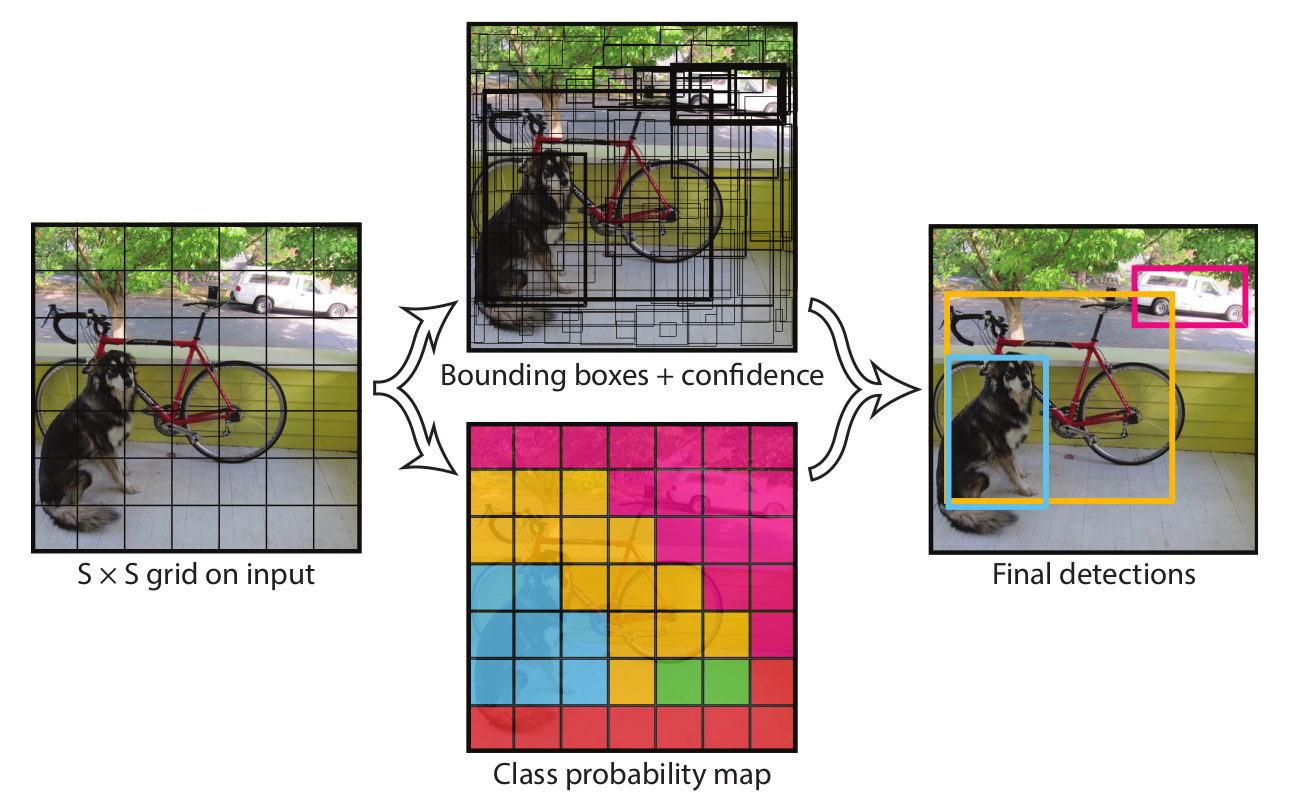
Detection 과정
- input 이미지를 S × S grid로 분할 (논문에서는 7x7)
- grid cell당 Bounding box와 Class probability 예측
- 각 그리드 셀은 bounding box B와 해당 box의 confidence score(신뢰도 점수)를 예측
- confidence score
- 해당 box가 객체를 얼마나 포함하는지, 그 정확도는 얼마인지 등 모델이 얼마나 신뢰 가능한지를 나타내는 점수
- confidence score = Pr(Object) ∗ IOU = 객체가 존재할 확률과 IOU 값의 곱
* IOU : 실제 객체 위치와 내가 예측한 객체 위치가 얼마나 일치하는지에 대한 지표 - box 내 객체가 존재하지 않으면 객체 존재 확률 Pr(Object)가 0이므로 confidence score = 0
- 각 bounding box는 x, y, w, h, confidence score로 구성 (x,y : box 중심좌표 / w,h : box 너비, 높이)
- confidence score
- 각 그리드 셀은 조건부 클래스 확률 Pr(Class i |Object)을 예측
- 그리드 셀이 객체를 포함할 때, 해당 객체가 i번째 클래스일 확률
- 각 그리드 셀당 확률값이 가장 큰 하나의 클래스만 예측
- 각 그리드 셀은 bounding box B와 해당 box의 confidence score(신뢰도 점수)를 예측
- NMS를 통해 최종 예측

- 위에서 예측한 수많은 bounding box들을 객체당 하나씩, 1:1 매칭되도록 NMS 방법 사용
- bounding box의 confidence socre와 IOU를 사용하여 NMS
- NMS (Non Maximum Suppression, 비최대억제) : 최대가 아니면 억제한다, IOU 값이 최대인 박스만 남긴다
- YOLO의 NMS 과정의 이해를 돕는 ppt 자료
- 최종 bounding box는 S × S × (B ∗ 5 + C) 텐서 형태로 표현
- (S × S grid cell 크기) x ( (한 grid cell당 예측할 bounding box 개수 B) * 5 + (class 개수 C) )
- 논문 예시로, 클래스가 20개인 데이터셋에 대해 이미지를 그리드 셀 7x7 크기로 나누고, 한 그리드 셀당 box를 2개씩 예측하려고 한다면, (7x7)x(2*5+20)=7x7x30 크기의 3차원 tensor
Network Design

- 전체 구조 : convolutional layers 24 (feature 추출) + fully connected layer 2 (확률과 좌표 예측)
- 1000 class의 ImageNet 데이터셋으로 20개의 conv layer를 pre-train
- 1 × 1 컨볼루션 레이어를 번갈아 사용해 선행 레이어의 feature space를 축소
- 활성함수 : leaky ReLU (마지막 layer만 linear 함수)
- 최종 output : 7 × 7 × 30 tensor (S=7, B=2, C=20)
Training
YOLO 네트워크는 손실함수로 SSE를 사용. SSE는 최적화가 용이하지만 아래와 같은 문제점 존재
- localization error와 classification error의 가중치를 동일하게 취급
- localization loss : bounding box의 위치를 얼마나 잘 예측했는지
- classification loss : 클래스를 얼마나 잘 예측했는지
- 모델 불균형 초래
- 일반적으로 이미지 내 객체가 존재하는 부분보다 없는 배경 부분이 더 많기 때문에,
grid cell 대부분의 confidence score = 0
- 일반적으로 이미지 내 객체가 존재하는 부분보다 없는 배경 부분이 더 많기 때문에,
- 모든 크기 bounding box의 가중치를 동일하게 취급
- 위치 변화에 민감한 작은 box와 그렇지 않은 큰 box의 가중치를 동일하게 취급
(box 크기 작을수록 옆으로 조금만 움직여도 객체 포함 여부가 달라질 수 있음)
- 위치 변화에 민감한 작은 box와 그렇지 않은 큰 box의 가중치를 동일하게 취급
이러한 문제를 개선하기 위해 사용한 두 가지 방법
- 가중치 조정
- 객체가 있는 BB 가중치 ↑, 객체 없는 BB 가중치 ↓ (BB : Bounding Box)
- λcoord = 5 / λnoobj = 0.5 (coord : coordinate prediction 좌표예측, noobj : no object)
- square root 적용
- Bounding box의 크기 차이를 감소시키기 위해 높이와 넓이에 제곱근을 적용
손실함수 이외의 조정한 파라미터 값
- Batch size = 64
- Momentum = 0.9
- Decay = 0.005
- Learning rate : 0.001 -> 0.01 -> 0.001 -> 0.0001 로 변화시키면서 학습
- Dropout과 Data Augmentation으로 과적합 방지
Limitations of YOLO
- 작은 객체 탐지가 어려움
- Spatial constraint (공간적 제약) : 그리드 셀 하나당 객체를 하나만 검출할 수 있어서, 한 셀에 작은 객체가 여러 러 개 모여있는 경우, 여러 객체를 검출하는 것이 아니라 하나로만 봐야하기 때문에 제대로 검출하지 못하는 문제
- 새로운 aspect ratio에 대한 탐지가 어려움
- aspect ratio : bounding box의 가로세로 비율
- 예를 들어, 1:1, 1:2, 2:1 비율의 bounding box만 학습했는데, 3:1 비율의 box를 테스트하면 탐지하지 못함
- 손실함수 SSE가 BB 크기와 관계 없이 가중치를 동일하게 취급한 문제를 해결하지 못함
- BB의 높이와 넓이에 루트를 취해서 크기 차이를 감소해 문제를 개선했지만, 가중치는 동일하게 주기 때문에 완전히 해결하지 못함
Conclusion
- 간단한 single network 구조
- 전체 이미지를 한 번에 train 및 detection
- 여러 구역으로 나뉜 이미지를 보는 게 아니라 전체 이미지를 봄으로써 새로운 도메인에 대한 일반화 능력 우수
* 추가 (논문 외)
일반화 능력 좋은 이유
- GAP (Global Average Pooling)
- 이전엔 CNN -> FC에 flatten 사용 : 단순히 펼치는 작업으로 선형성이 사라짐
- 따라서 convolution 연산인 GAP 사용
- 3*3*4096 -- GAP --> 1*1*4096 (4096:channel)
- 즉, 사실은 conv layer인데 fc layer처럼 사용
=> 지역적이지 않고 global하게 전체 이미지를 봄으로써 보다 일반적인 feature로 객체 인식 가능



